PortfolioDev Agrawal
4 minute readServerless Deployment06-16-2022
TechnologySoftware Development

Image sourced from Hexaware
This infamous depiction of serverless has been circulating around for years now. According to this image, Serverless Functions, also called "Functions as a Service", is way to write an application with a focus on business logic and not worrying about infrastructure or runtime.
I'm new to serverless, how does this work?
Well if you're written traditional web apis before, it might look something like this -
// index.ts
import express from "express"
import Cat from "./models/cat"
const app = express()
app.get(`/`, async (req, res) => {
const cats = await Cat.findAll()
res.json({ cats })
})
app.listen(process.env.PORT)
To have a similar application on a serverless platform like AWS Lambda, your code would look like this -
// handler.ts
import Cat from "./models/cat"
export const getCats = async (event) => {
const cats = await Cat.findAll()
return { data: { cats } }
})
Instead of express (or any other web framework) registering this function as an API handler, Lambda registers it as a handler function, which can configured to be triggered by a variety of events/conditions (including http requests).
# serverless.yml
functions:
get-cats:
handler: handler.getCats
events:
- http:
path: /
method: get
Serverless Framework Configuration
This can now be deployed to Lambda using the AWS CLI (or something vendor-agnostic like the serverless framework). Based on the configuration file, when a trigger event happens, a new container will spin up and execute this function.
You just wrote some code and deployed it without thinking about any infrastructure or runtime!
Execution On Demand
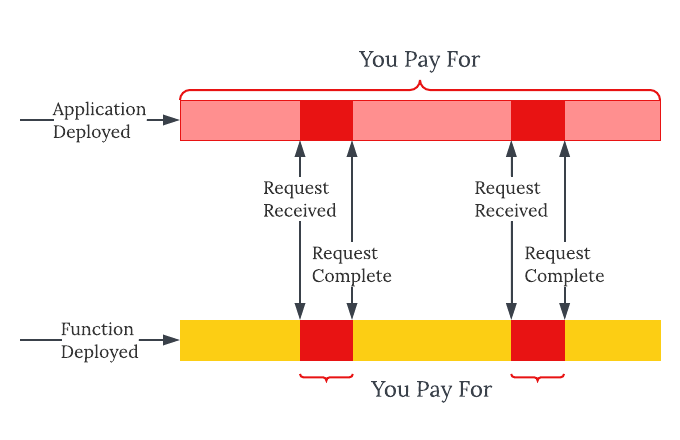
When you deploy traditional apps, you (or your trusty Continuous Delivery service) will spin up a container, start your application process inside the container, establish a network connection, and send an alert to your slack channel. This application will now wait for network requests and react to them as told. All this while, it's consuming memory and processing power, even when it does not receive any requests.

In comparison, when you deploy a serverless function, a service like Lambda will only bill you for the time your function is actually running, which only happens when it's triggered. When there is a trigger event, Lambda will find the corresponding function for that trigger, then either spin up a new container and load the function in it (cold start) or find an existing container that has the function already loaded in memory (hot start), and execute the function. The container will then either stay on and wait for more requests, or die out.

So you can start to notice some differences here. If you receive 1 request every second, you will only have 1 running function every second. However, if you get a thousand requests at the same time, Lambda will run a thousand containers with the function. So this approach is extremely elastic. You will use and pay for only the exact resources that you use. If you have multiple functions, each function is deployed as a separate Lambda, so you also will only be using the resources required to run that one function.
So it's always cheaper?
Not really.
For a base unit of computation (like an hour of server usage), you will pay more to the serverless service than you would for a virtual server.
AWS EC2 can cost between $0.008 to $0.01 per hour for an instance with 1 GB of memory.
Sources: EC2 Pricing, Lambda Pricing
The difference lies in how much computation you are using. With a virtual server, you are paying for every second the server is alive, regardless of whether your code is running in it. In comparison, a serverless function will only cost you the computation of the function itself.
It's optimized for elasticity, so it's only feasible in scenarios where you need elasticity. If you have inconsistent or unpredictable usage, serverless is a nice fire-and-forget deployment method where you app will scale up and down automatically as needed.
If you have some consistent patterns in usage, and you don't mind having to manage containers or servers, serverless is probably not going to be feasible for you.

How do I start then?
Well, hold your horses.
There is one other case where you can't simply deploy to serverless. If your application is currently in a state of spaghetti, serverless will cause more pain than harm.
Since your functions are loaded and executed separate from each other, you can apply a lot of the principles of Microservices here. The functions should be small, independent, and fulfil a single responsibility. I have another post coming up on Microservices, that's where I'll talk more about the purpose and strategy behind Microservices.
Serverless seems (for now) to be the pinnacle of what cloud technology is hoping to achieve - allowing us, the developers, to write code that serves business functions with minimal management of the infrastructure that the code will run on.